Scaling on AWS for 10 million users
- App = user-interfacing layer + business logic layer + data storage
- Acknowledge current technology trends: modern JavaScript frameworks, Full-stack frameworks, moving away from self-managed/DIY infra to managed services, potential for rapid scale (measured in hours, not days)
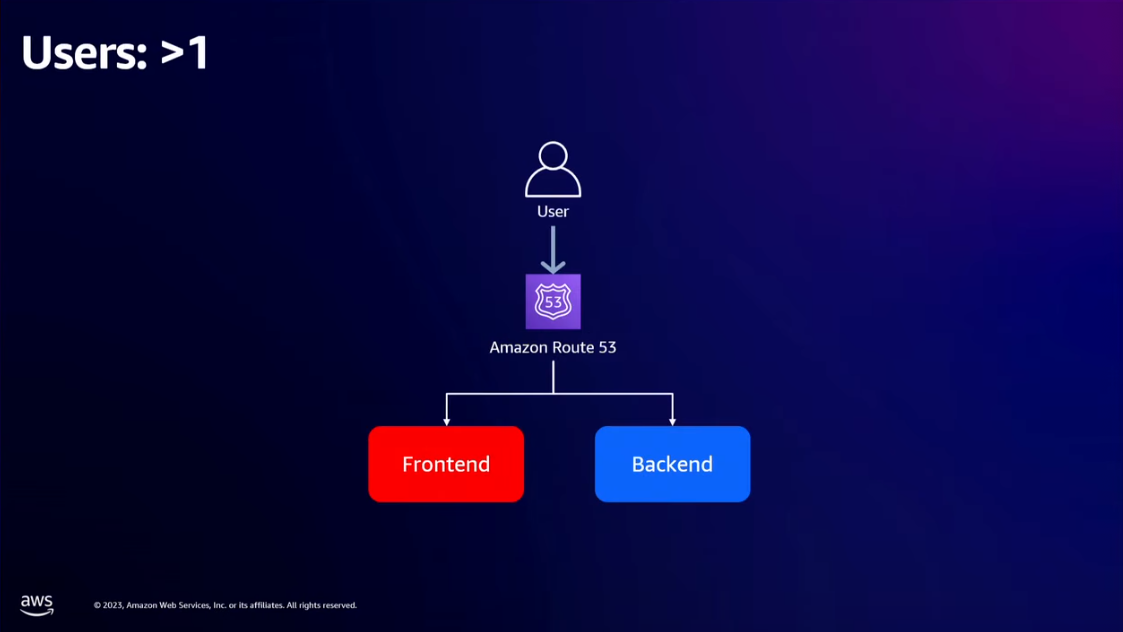
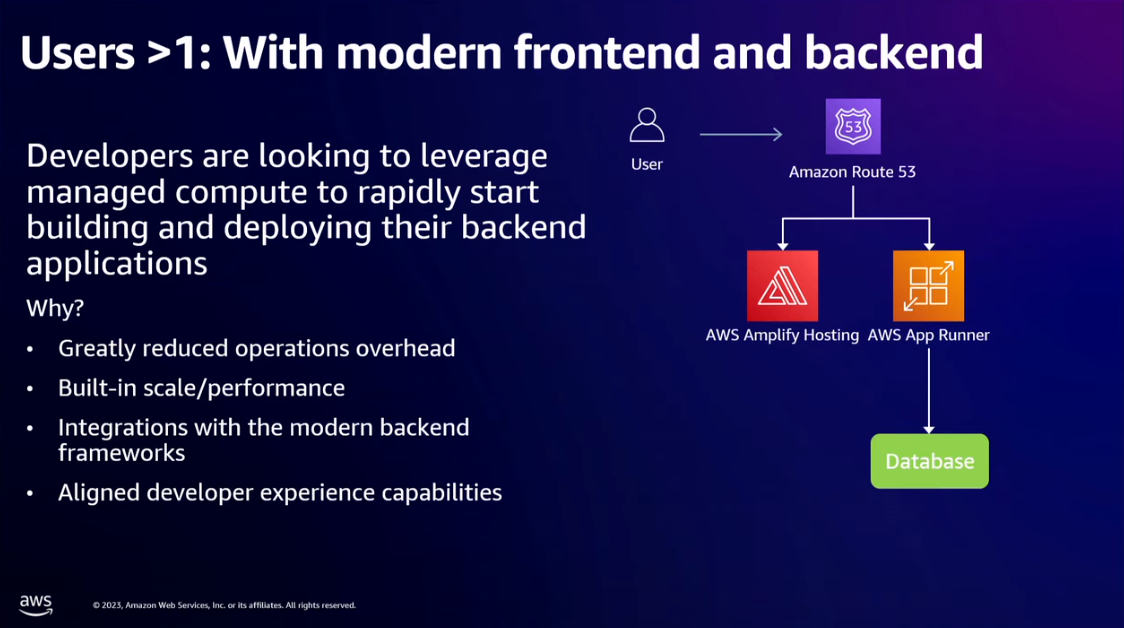
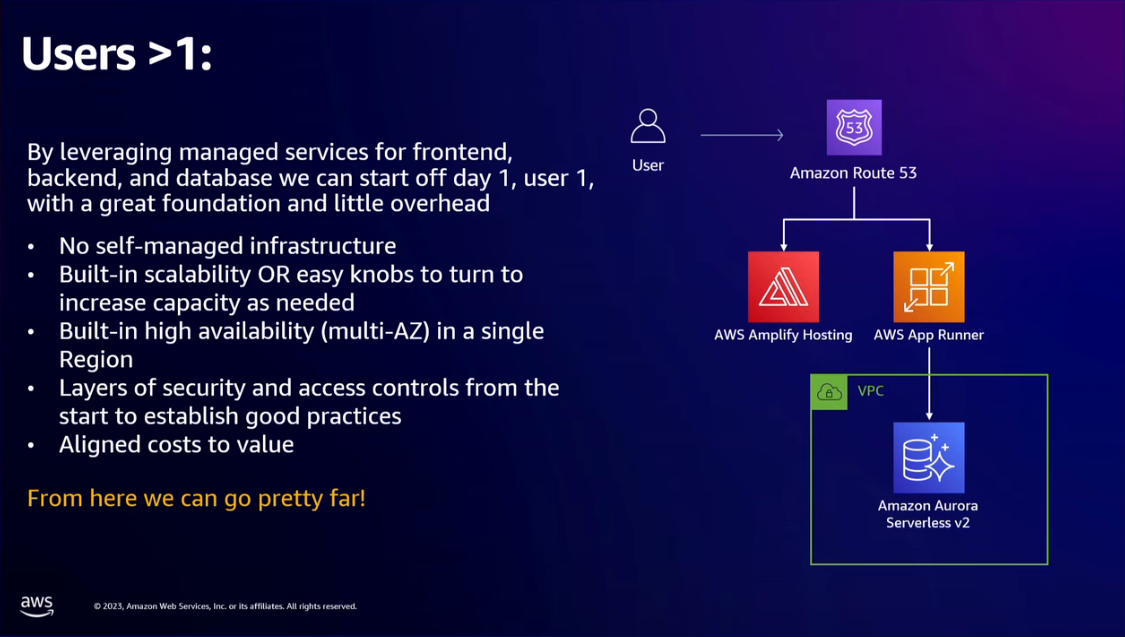
- Users > 1
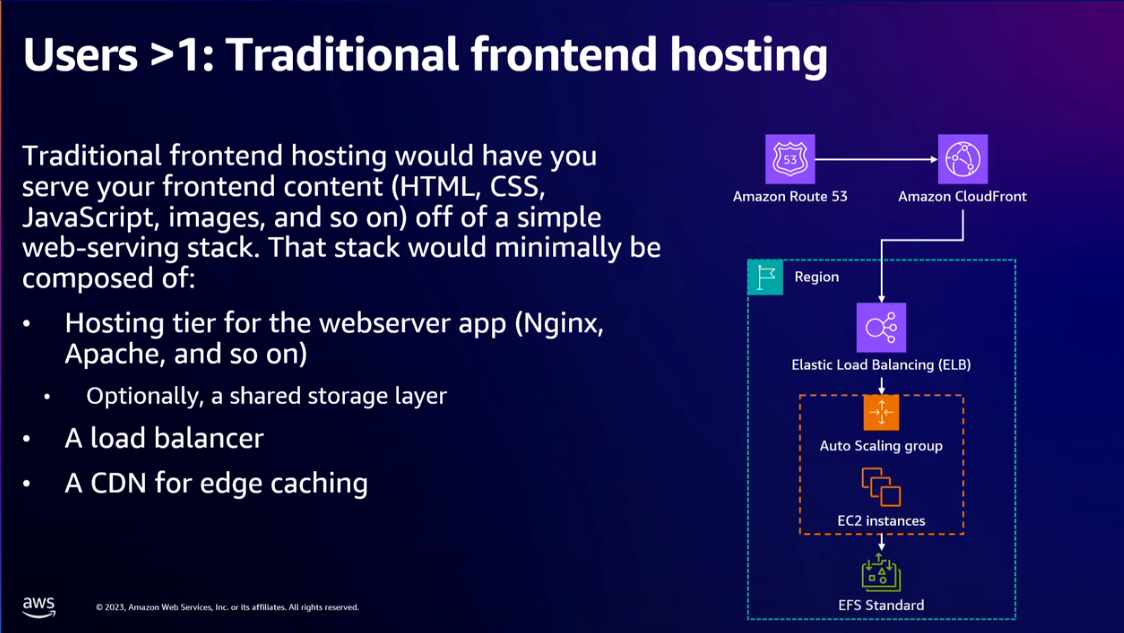
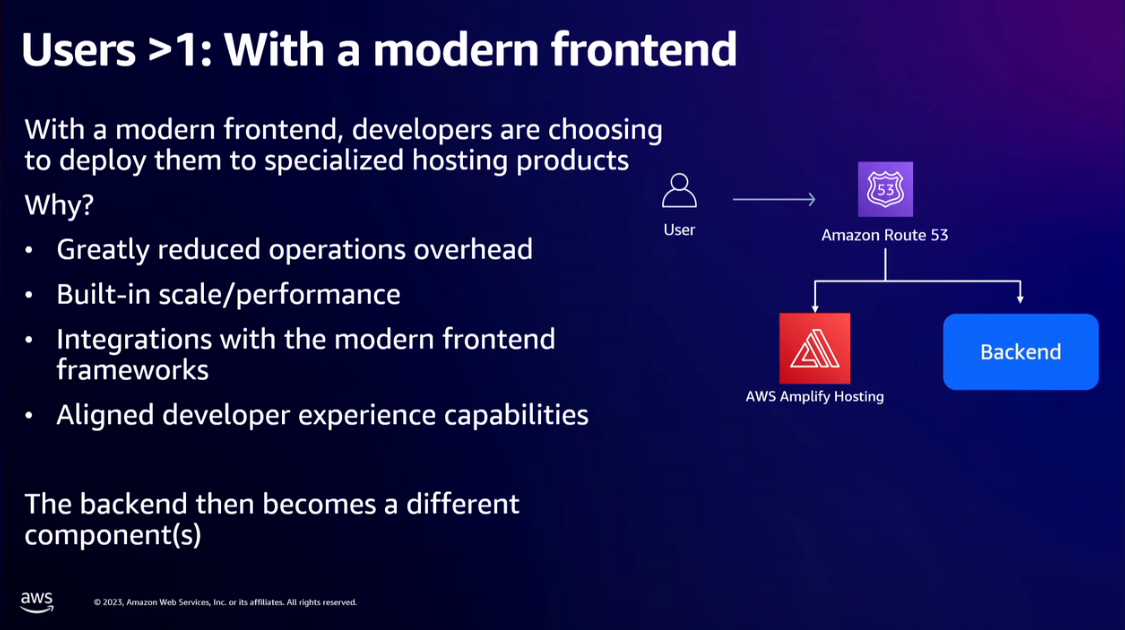
- Use a self-hosted service like AWS Amplify to host the frontend instead of setting up your nginx webserver with load balancing etc.
- For the backend, you can use
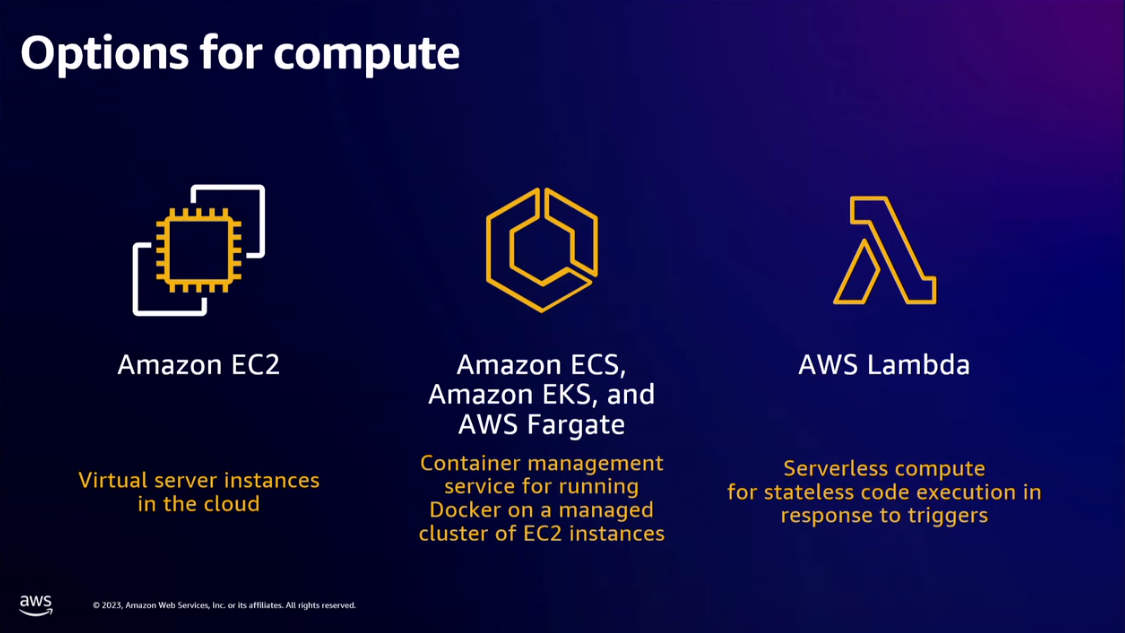
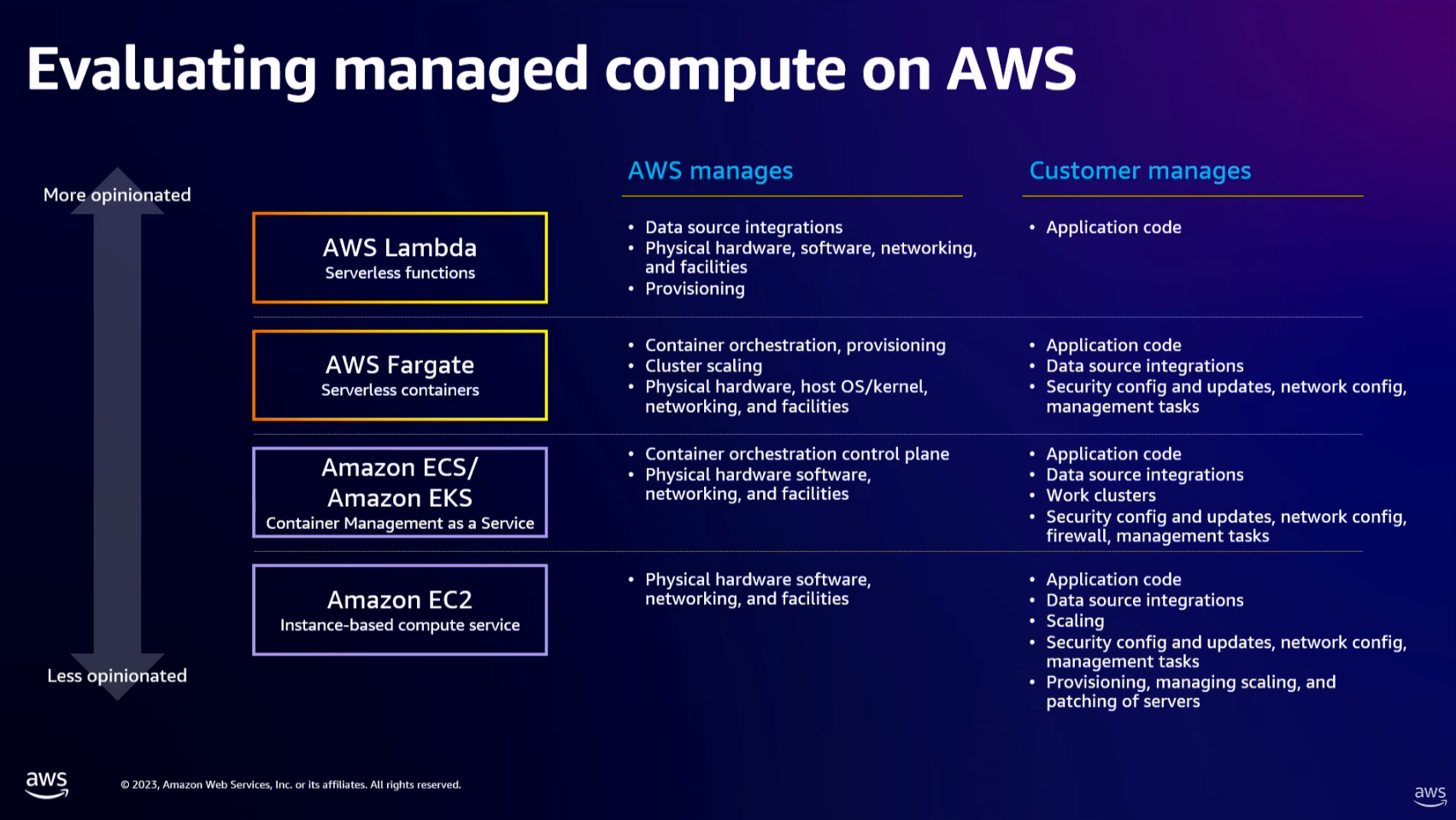
- virtual server instance on the cloud: Amazon EC2
- Container management service for running Docker on managed cluster of EC2 instances: Amazon ECS, Amazon EKS and AWS Fargate
- Serverless compute: AWS Lambda
- 3 options for exposing API:
- Amazon API Gateway
- Application Load Balancer
- AWS AppSync
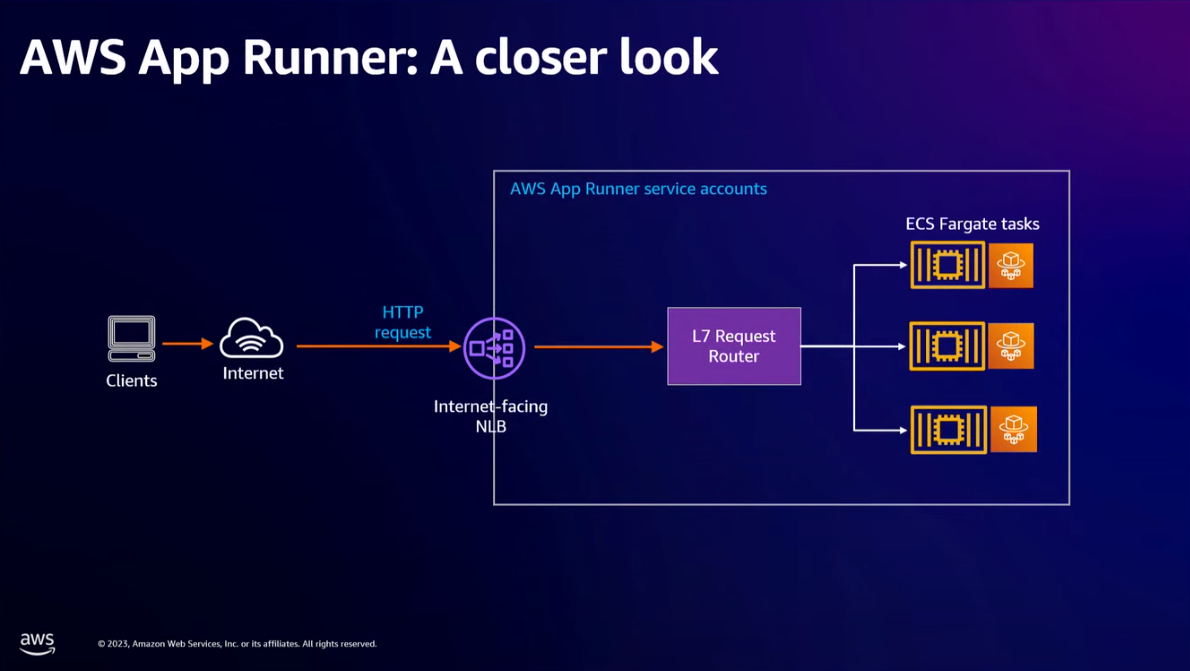
- Another option is the AWS App Runner for both the backend server and to expose the APIs to the frontend.
- For database, choose SQL vs NoSQL -> Start with SQL database. Unless you have a "massive" amount of data. "Massive" here means multiple terabytes of data in year 1 or an incredibly data-intensive workload.
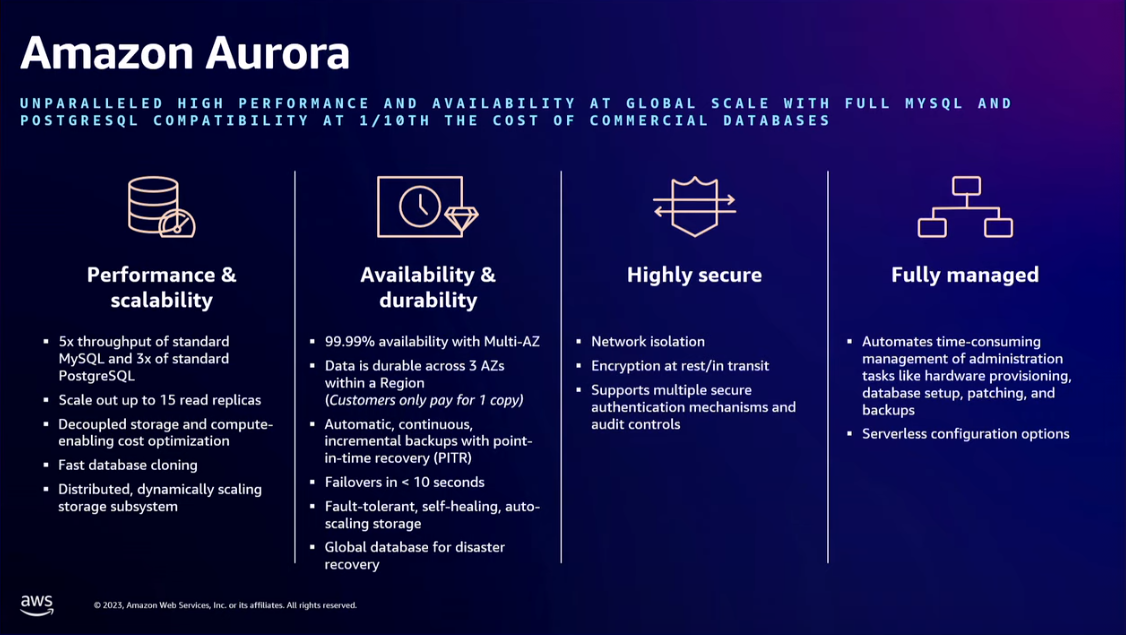
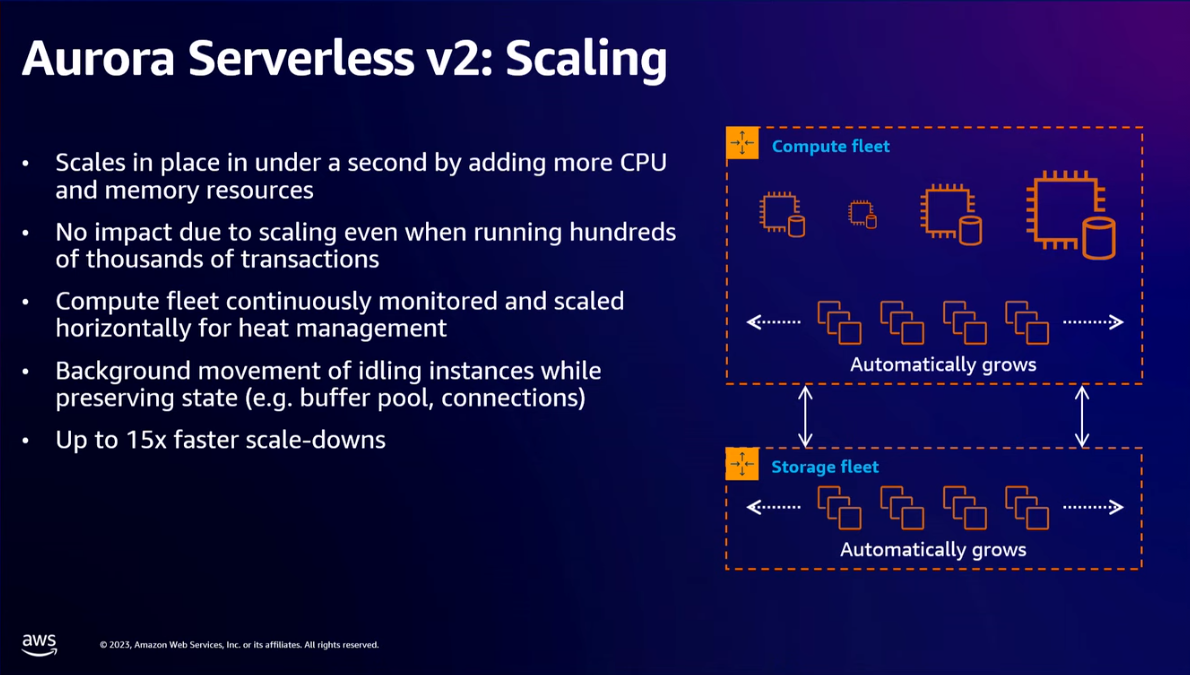
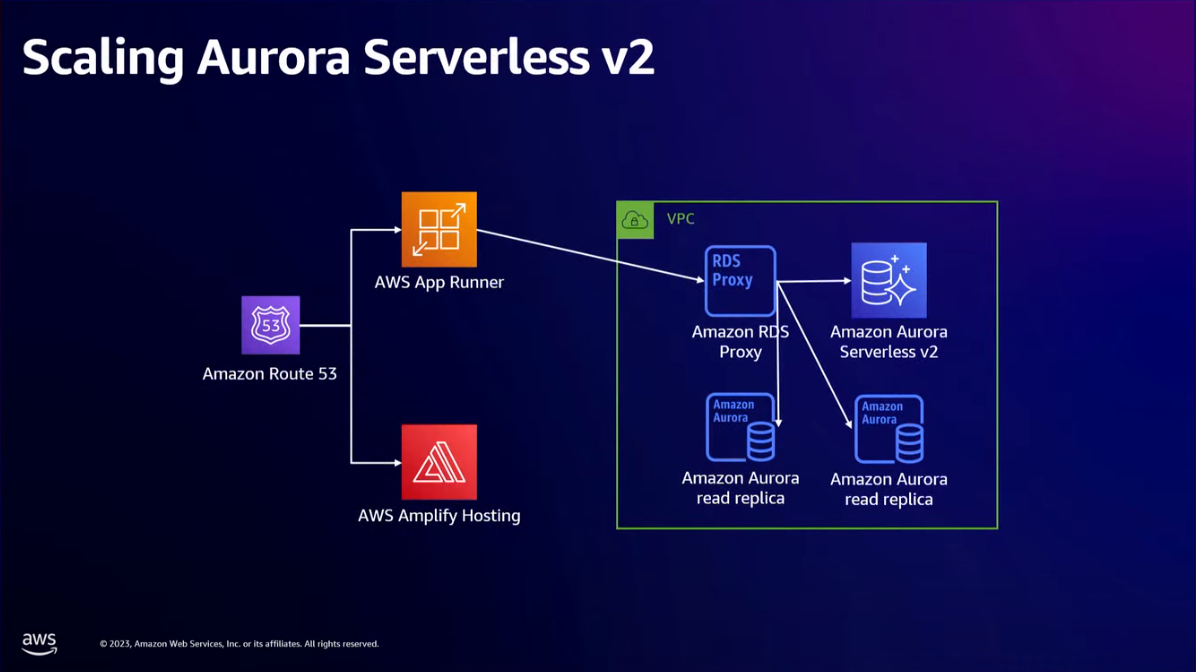
- You can host the SQL relational database (MySQL and PostgreSQL) on Amazon Aurora. It supports auto-scaling. Use Amazon Aurora Serverless v2 to decouple the compute and the storage layer in fine-grained increments. This is important to reduce the cost. It will autoscale the databases only when there's a high load from your users, and then it will scale down again.
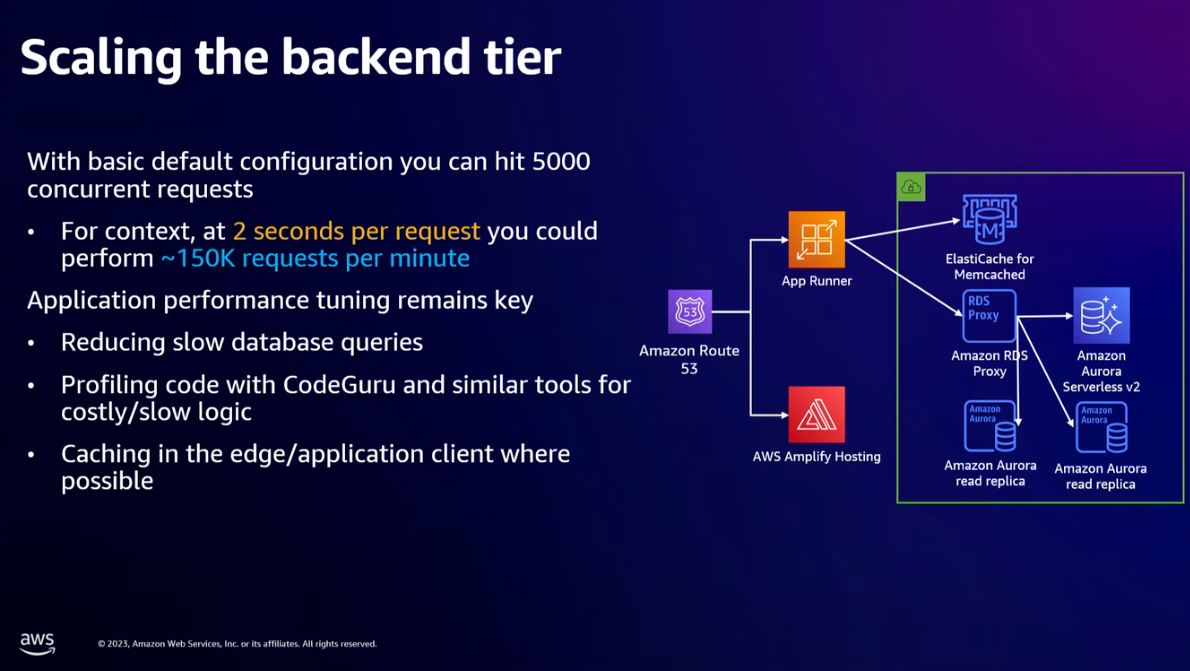
- Now our modern app on AWS is made of AWS Route 53 (for DNS), AWS Amplify Hosting (for hosting frontend), AWS App Runner (for both backend servers and exposing the APIs), and Amazon Aurora Serverless v2 (for relational database).
- Users > 10000
- Things will start to break. Mainly because our architecture is still monolithic.
- We can't tune what we aren't measuring. We need to add some toolings! e.g. Amazon CloudWatch and AWS X-Ray.
- Leverage ML to assist you e.g. Amazon DevOps Guru and Amazon CodeGuru.
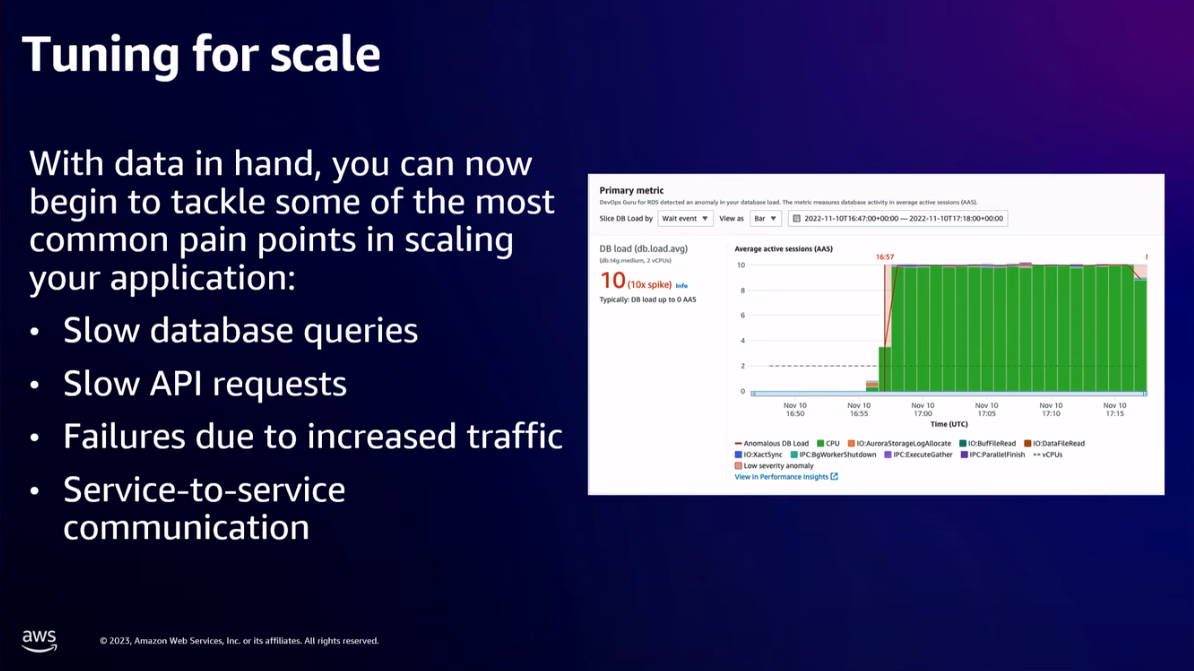
- Now you can monitor/notice the slow API queries, the slow database queries, and network failures, so you can improve it.
- Scaling the frontend: Use Amazon CloudFront for CDN to cache static contents such as images, JavaScript and CSS.
- Scaling the data tier:
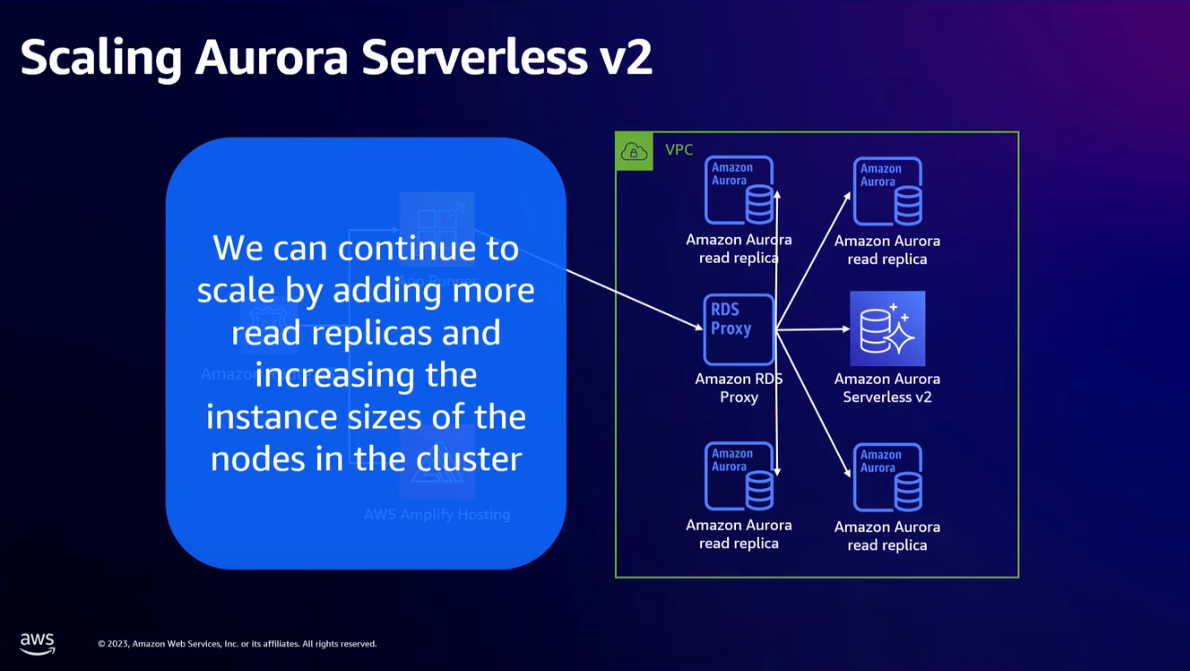
- You will get to the point where either compute or storage is your bottleneck. Amazon Aurora Serverless v2 detach these 2 so that you can scale it independently.
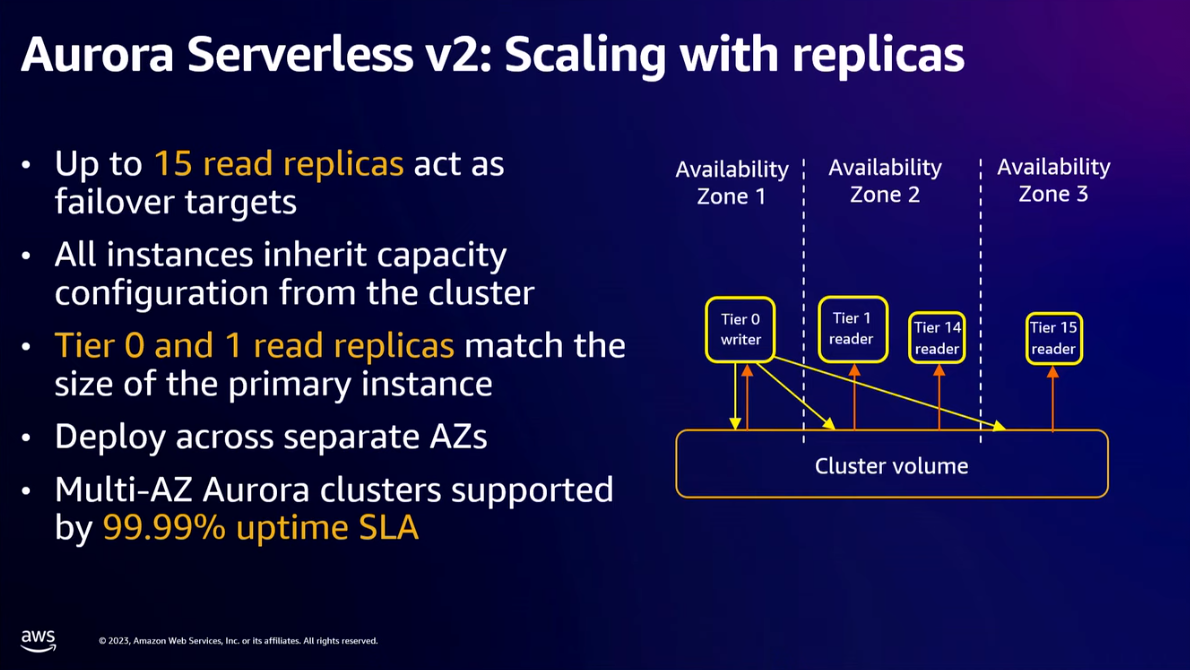
- Aurora Serverless v2 supported up to 15 read replicas. When you have added read replicas and grow the Aurora clusters. Some customers have 20:1 to 30:1 read:write demand, and they will add a database proxy such Amazon RDS Proxy. Database proxy has been around in the MySQL and PostgreSQL world for a long time.
- A single write master in Aurora can have up to 120 ACUs (Aurora Capacity Unit) and 15 read replicas. "120 ACUs" is a measure of the computational and memory capacity of the Aurora Serverless v2 database. One ACU has a certain amount of compute and memory capacity.
- RDS Proxy is a database proxy that sits between your application and all of your database nodes (both read and write nodes). This helps to simply handle connection and memory consumption. Being able to have RDS Proxy own the connection pools reduces resource demand on the database.
- "The best database queries are the ones you never need to make (often)."
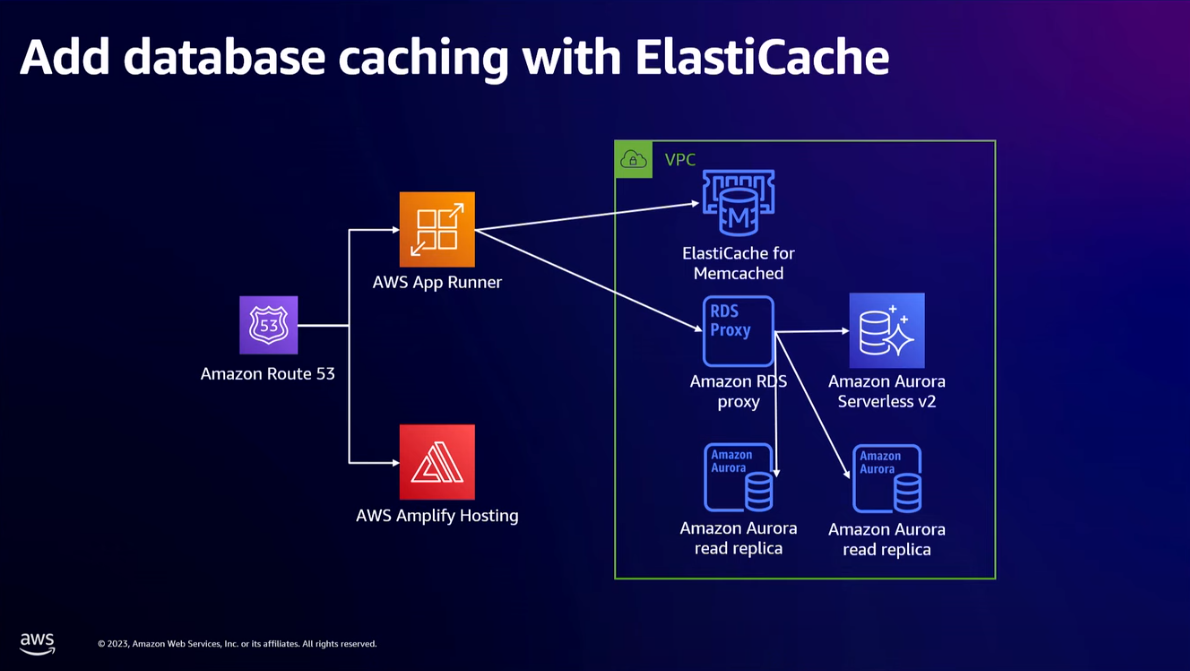
- Add cache in front of the database. You can use Amazon ElastiCache for a managed Memcached or Redis.
- Summary for scaling the data tier
- Increasing the size of the instance(s) used
- Adding read replicas and a proxy to help scale the read queries — typically minor application changes
- Using caches to remove queries from even needing to be made — requires significant application/logic changes
- Scaling the backend tier:
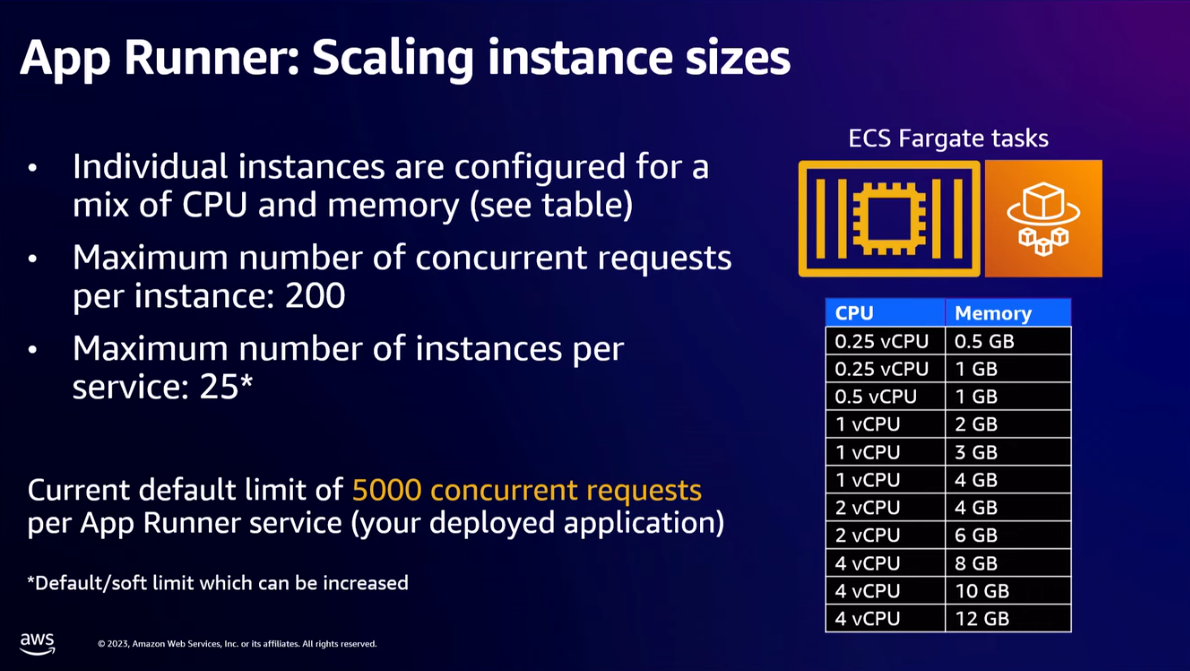
- App Runner instances (runs using ECS Fargate tasks) are configured for a certain amount of memory and CPU (from 0.25 vCPU and 0.5 GB memory to 4 vCPU and 12 GB memory).
- Scaling factor 1: every App Runner instance has maximum default concurrent requests it can handle (this is not TPS, this is concurrent requests). The upper hardbound is 200 requests.
- Scaling factor 2: the number of instances per service/application has a default soft limit of 25.
- max concurrent request per App Runner service (your deployed application).
- App Runner will manage to scale the tasks for you. It automatically adds instances to the request router when there's an increase of concurrent requests sent to an instance. Instance not serving requests will go idle, and when there are no requests, App Runner scales down to 1 (default) while still keeping the memory provision to minimize cold start latency.
- In a traditional auto-scale model with EC2, when you scale down a node, you have no idea what that thing is doing. Here, the L7 Request Router tracks the in and out requests.
- With default 5000 concurrent requests, at 2 seconds per request, you could perform ~150k requests per minute per instance.
- This will scale our application to a million users.
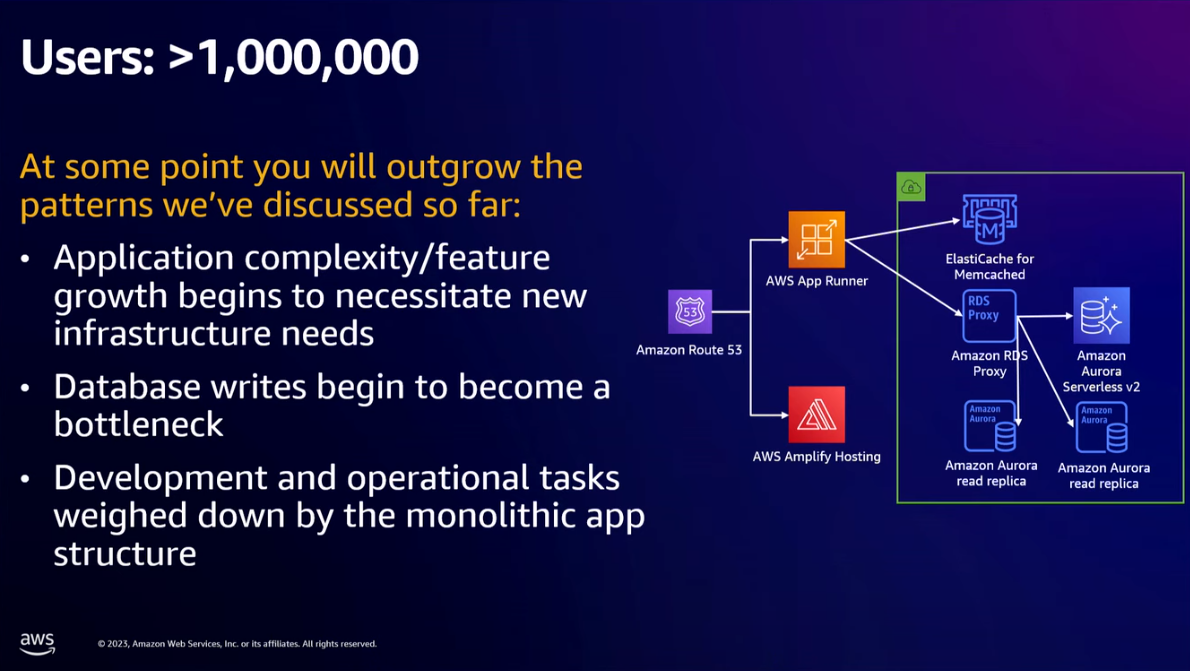
- Users > 1,000,000:
- You will outgrow the patterns we've discussed so far:
- The application will have new infrastructure needs because of the growth of the complexity/feature.
- Database write become a bottleneck
- The monolithic app structure slows down development and operational tasks
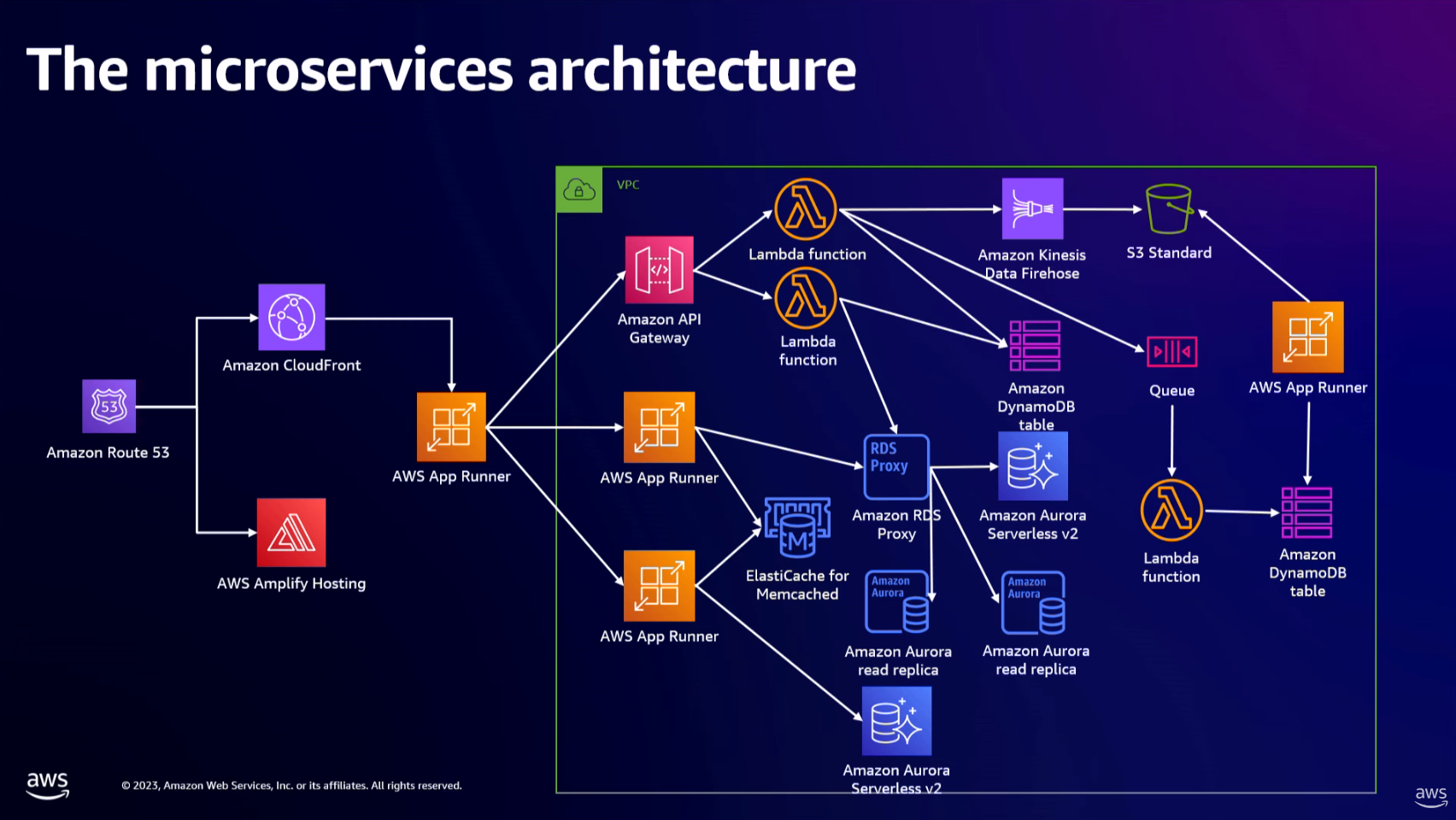
- Microservices: Move to SOA (service-oriented architecture) or microservices-based architecture.
- Scaling data tier:
- Have more databases. Database federation is a technique to split up databases by function/purpose.
- Shifting some functionality to use NoSQL using Amazon DynamoDB.
- Scaling the backend tier:
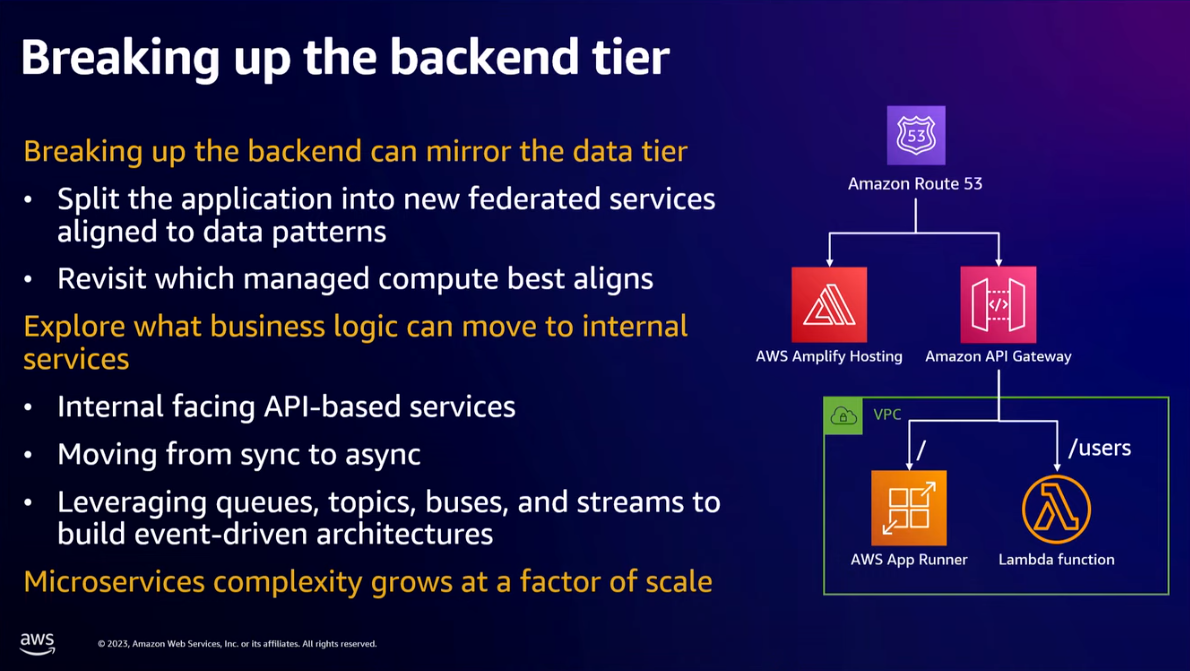
- Breaking up the backend tier into microservices by mirroring the data tier. A single App Runner application becomes multiple App Runner applications.
- How to glue everything together between multiple backend services to the client? Amazon API Gateway has a "base path mapping" that allows you to map different parts of your API to different backends. Different teams can own a different path for their API.
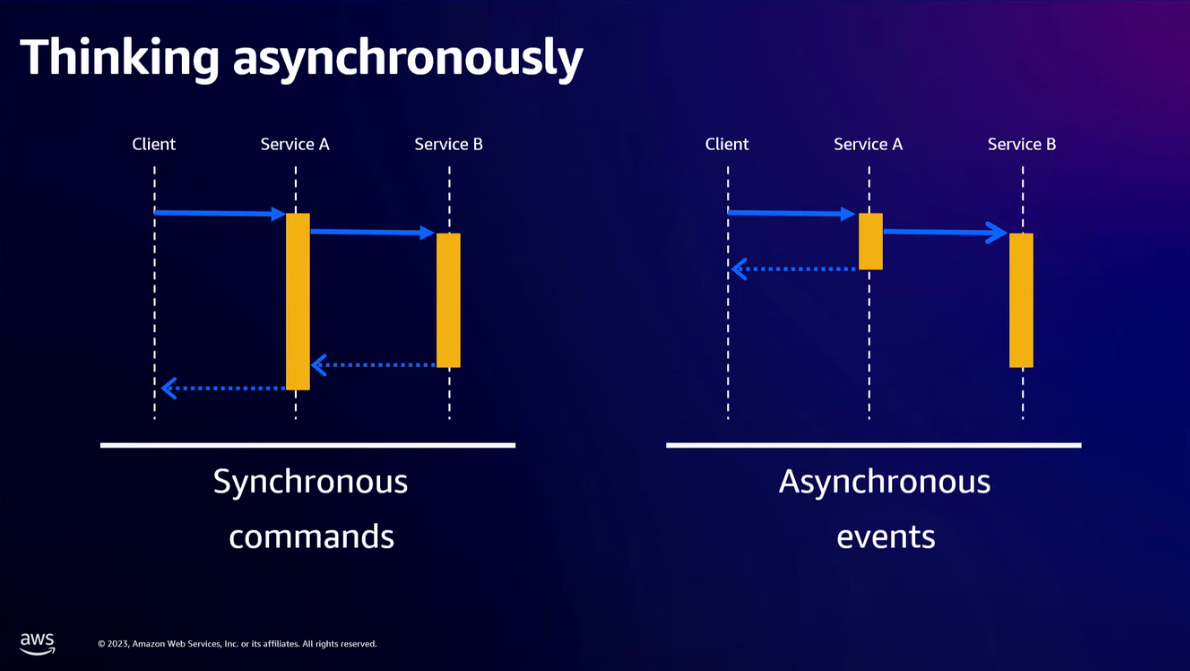
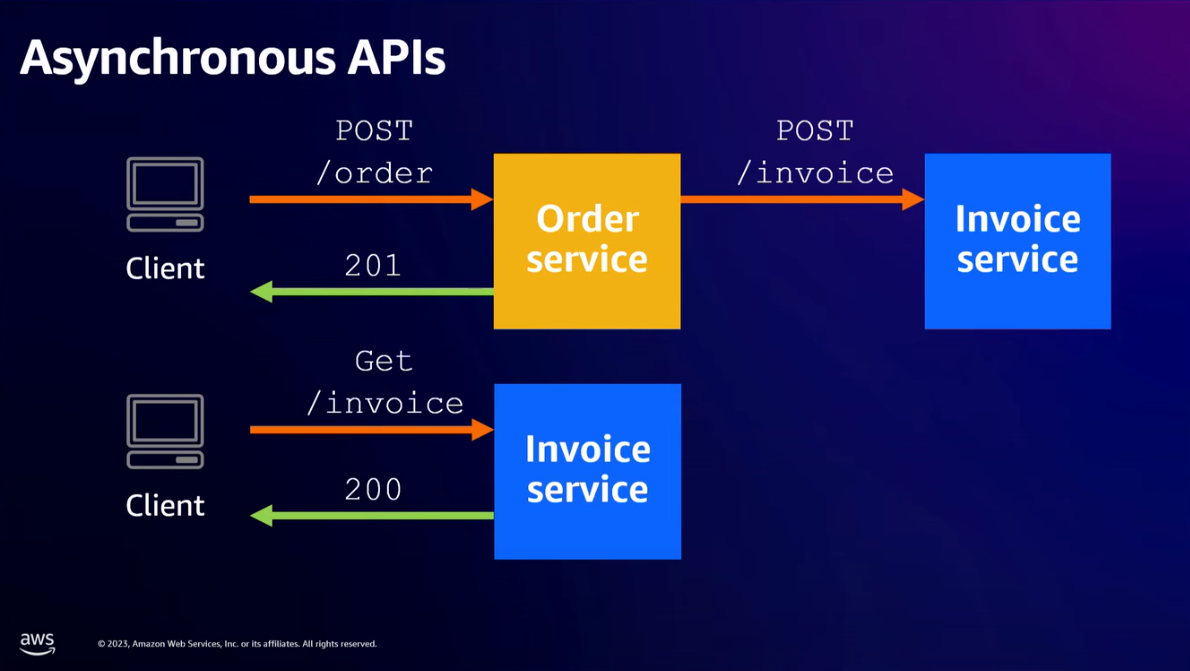
- Exposing APIs inside of our infrastructure microservices is not what we should do -> Move to different technology patterns from synchronous model APIs to asynchronous model APIs. This will change our architecture from tightly coupled to loosely coupled architecture.
- "The time spent to try making a process async will pay for itself in you gaining a deeper understanding of what is happening with your data."
- Beyond having API calls to API calls, there are other ways to pass events from Service A to Service B. You can use topics, streams, queues, and buses e.g. Amazon SNS (Simple Notification Service), Amazon SQS (Simple Queue Service), Amazon EventBridge (basically a message bus hub between different services), and Amazon Kinesis Data Streams (allows you to ingest information fast and spread out information at scale).
- When to use which of these asynchronous services?
- Massive throughput/ordering/multiple consumers/replay? -> Amazon Kinesis Data Streams
- One to mostly one or minimal fanout, direct to Lambda/HTTP target? -> Amazon SNS
- Buffer requests until they can be consumed, whether order or not? -> Amazon SQS
- One to many fanout, lots of different consumer targets, schema matching, granular target rules? -> Amazon EventBridge
- You will outgrow the patterns we've discussed so far:
- Users > 10,000,000
- At this scale, the architecture will start to look more unique for different companies.
- Uber and Amazon had thousands of microservices that all look almost the same and follow the same types of scaling patterns.
- Only respond and make changes when there's a certain breakpoint.
- You want to be able to dive really deep into your stack performance. Your observability tools, monitoring tools, and code profiling tools become incredibly important, key, and critical to understanding where and how to scale further.
- This might be the point where you might want to self-manage certain components of the architecture yourself if the cost makes sense. For example, Lambda is the most expensive way to buy computing at AWS, so you might want to take back that responsibility and build it yourself.
- Closing notes:
- The bulk of scaling wins come from doing less
- Caching at both the edge and origin (server tier and database tier).
- Reducing the scope of database queries and data processed
- Evaluate refactoring cautiously
- Federating data can still be an easy way to win
- Look for "best fit" technologies based on need. App Runner might not work for you, and that's fine.
- The bulk of scaling wins come from doing less
Slides